|
 INTRO
LEVEL INTRO
LEVEL
Why data compression?
Data compression is one of the most important
enabling technologies of the information age.
Various forms of compression are part
of almost every multimedia application. Without compression,
we wouldn't be able to put images, let alone audio or video
on the Internet. Long-distance calls, modems, fax machinesall
rely on compression. If it weren't for compression, cell
phones would not be improving in clarity, we wouldn't have
digital TV or satellite communications.
Example of data compressionMorse
Code
Morse code is an early example of data
compression from the 19th century developed by
Samuel Morse. To send a message, letters are transmitted
via telegraph are encoded as a series of dots and dashes.
Morse realized that certain letters are used more frequently
than others, so in order to reduce the time necessary to send
a message, he assigned shorter code sequences to letters that
occurred more often such as "a" 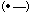 and longer ones to letters that appear less often, like "q"
and longer ones to letters that appear less often, like "q"
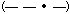 . .
What is a compression algorithm?
A compression algorithm is the mathematical
process for converting data into smaller packages. A compression
algorithm actually consists of two parts. There is the encoding
algorithm, which takes an input X
and generates a representation Xc
that requires fewer bits, and there is a decoding
algorithm that takes Xc and reconstructs
it as Y. With lossless compression,
X=Y.
What is lossless compression?
Lossless compression, as the name implies,
involves no loss of information. If an image has been losslessly
compressed, the original data can be recovered exactly from
the compressed data. Lossless image compression is used primarily
for archiving, since people want to save all of the original
data. TIF and LZW-TIF are commonly used lossless compression
schemes. Generally, images can be losslessly compressed at
rates of about 2:1.
What is lossy compression?
Lossy compression techniques involve
some loss of information. As a result, the original image
cannot be exactly reconstructed. In other words, the image
you get out of decompression isn't quite identical to what
you originally put in. In return for accepting varying levels
of distortions and artifacts in the reconstruction, higher
compression ratios are possible. JPEG is the most common
form of lossy compression.
What is visually lossless compression?
The term visually lossless is a misnomer.
Visually lossless compression is actually lossy compression
at low rates. It means that the compressed file is "visually
indistinguishable from the original", however there is
still loss involved in the compression. Lossless compression
is a mathematical guarantee, visually lossless compression
is subjective and means "close enough".
INTERMEDIATE
LEVEL
What is a JPEG?
JPEG is a standard for representing images
that was created in the late 1980s. There are many different
modes of JPEG including baseline, lossless, progressive and
hierarchical. The baseline mode is the most popular mode
and supports only lossy coding. There is a lossless-only
mode of JPEG, but it never gained popular acceptance and is
largely obsolete.
JPEG baseline divides an image into 8x8
blocks and compresses
To be continued...
|
